형태소 분석을 위해 CounterVectorizer를 생성하면서 문제가 생겼다.
# countvectorizer 생성
from sklearn.feature_extraction.text import CountVectorizer
실행시 아래와 같이 에러 메시지가 떴다.
ImportError: DLL load failed while importing _arpack: 지정된 프로시저를 찾을 수 없습니다.
sklearn을 비롯해, 혹시 몰라 numpy, scipy 등을 재설치 해 보았으나 계속 동일한 에러가 발생했다.
결국 jupyter notebook을 삭제하기 위해 cmd 관리자권한으로 창을 띄우고 python을 실행시켜 보니 아래와 같은 메시지가 출력됐다.


위 CMD 창에 뜬 https://conda.io/activation
내용을 참조하여 anaconda prompt 상태에서 c:\Anaconda3\Scripts\activate base를 실행시킨다.

이제 python을 실행시켰을때, 에러메시지가 뜨지 않는다.(하지만, CMD에서 실행할 경우 위 문제는 해결되지 않는다.)
다시 jupyter notebook을 실행시킨후 다시 해당 코드를 실행하면 잘 수행된 것을 확인할 수 있다.(꼭, anaconda prompt에서 jupyter notebook을 실행시켜야 한다.)
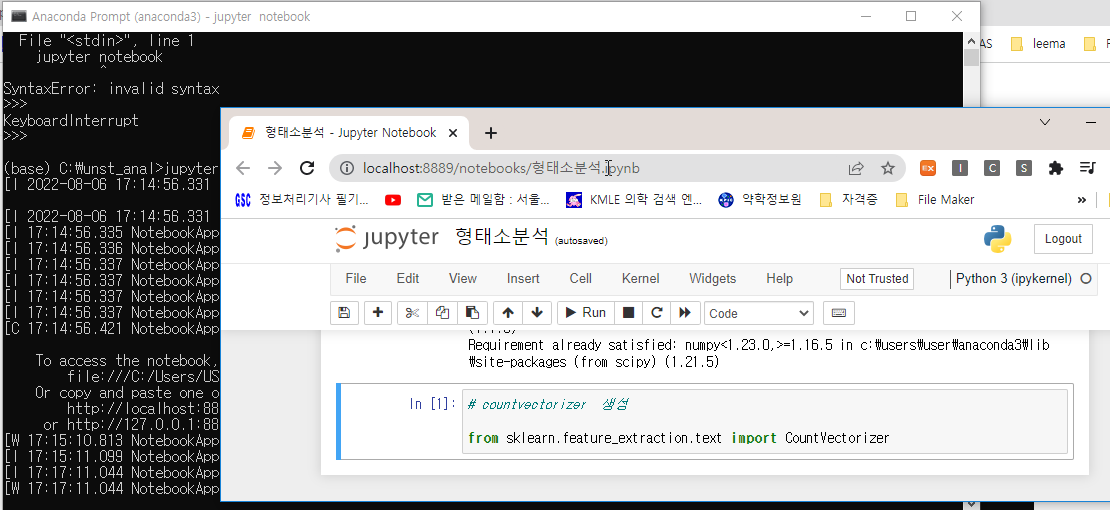
결론적으로, 내가 행했던 오류는....
CMD에서 jupyter notebook을 실행했다는 것이다.
Anaconda3 CLI(Anaconda Prompt)에서 jupyter notebook을 실행시켜야 한다.
생각해보니 기본중 기본 아닌가?? 똥멍충이같다ㅠㅠㅠ.
'Programming Language > Python' 카테고리의 다른 글
| [Python]파이썬 프로그램 실행중 강제종료 (0) | 2022.06.21 |
|---|---|
| [Python]데이터프레임을 문자열로 변환하기(numpy array to pandas series로 형태로 변환) (0) | 2022.06.16 |
| [Python]escape code (0) | 2022.06.16 |
| [Python]excel file 불러와서 특정 컬럼 추출 후 정렬, 인덱스 리셋 (0) | 2022.06.16 |